Programmatically Grounded, Compositionally Generalizable Robotic Manipulation
Abstract
Robots operating in the real world require both rich manipulation skills as well as the ability to semantically reason about when to apply those skills. Towards this goal, recent works have integrated semantic representations from large-scale pretrained vision-language (VL) models into manipulation models, imparting them with more general reasoning capabilities. However, we show that the conventional pretraining-finetuning pipeline for integrating such representations entangles the learning of domain-specific action information and domain-general visual information, leading to less data-efficient training and poor generalization to unseen objects and tasks. To this end, we propose ProgramPort, a modular approach to better leverage pretrained VL models by exploiting the syntactic and semantic structures of language instructions. Our framework uses a semantic parser to recover an executable program, composed of functional modules grounded on vision and action across different modalities. Each functional module is realized as a combination of deterministic computation and learnable neural networks. Program execution produces parameters to general manipulation primitives for a robotic end-effector. The entire modular network can be trained with end-to-end imitation learning objectives. Experiments show that our model successfully disentangles action and perception, translating to improved zero-shot and compositional generalization in a variety of manipulation behaviors.
Method
Zero-Shot Generalization
Our benchmark extends the Ravens manipulation benchmark (Zeng et al., 2021 and Shridhar et al., 2022). In the zero-shot portion of our test suite, tasks involve manipulating completely new objects, as well as objects of drastically different properties (shape, color or size).
Compositional Generalization
We first train on tasks containing different objects, object properties such as color or shape, and other vision-language descriptors like relative spatial position. At test-time, we ask the agent to reason about novel combinations of concepts seen independently during different training tasks. For example, our training-testing flow for the packing-shapes task is shown:
Disentangled Vision and Action
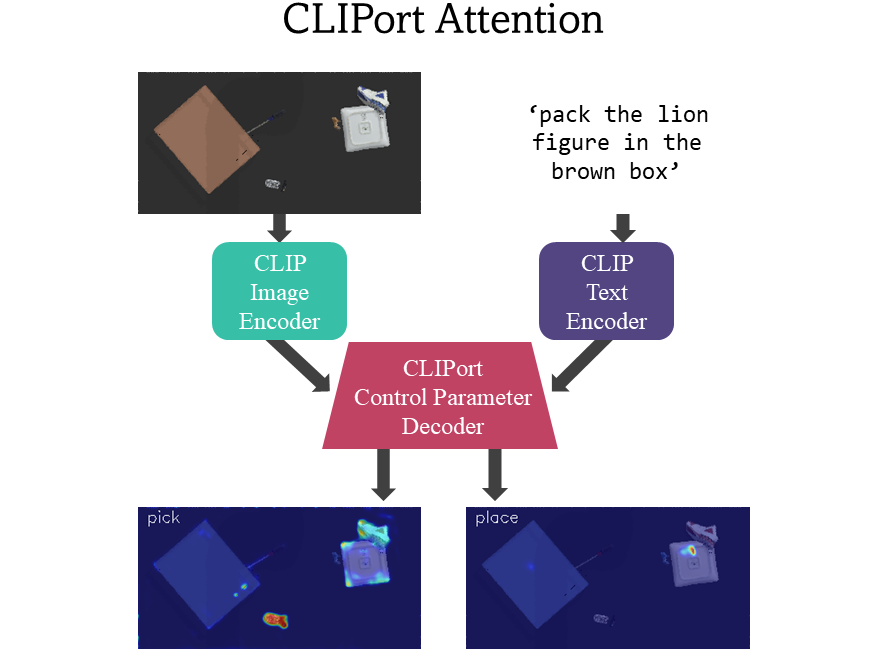
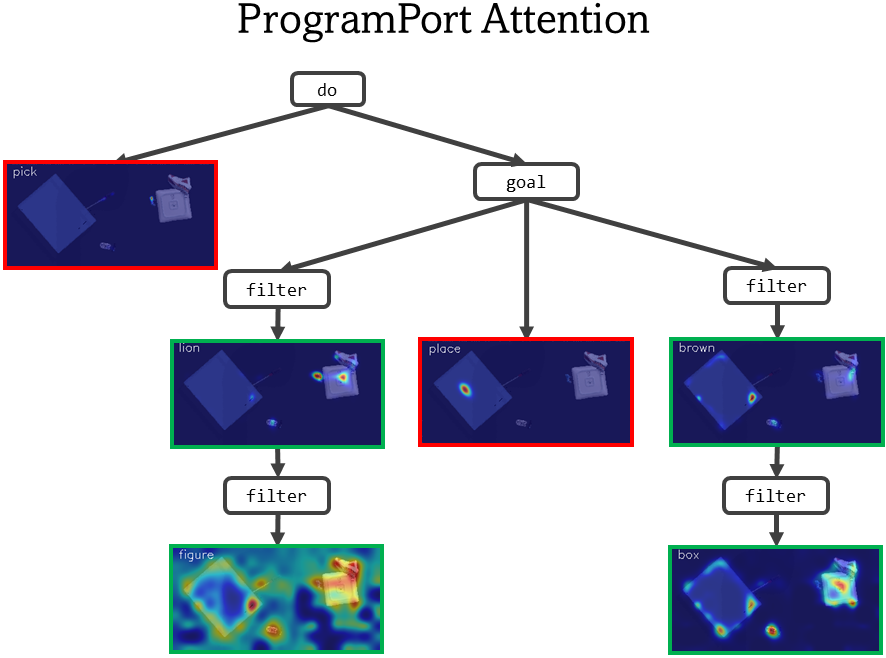
ProgramPort's excellent performance is enabled by disentangling vision-language grounded from action
understanding. Our modular design disentangles the learning for visual grounding modules,
which identify and ground to a single visual concept at a time, and action modules,
which parameterize general robotic manipulation primitives like picking and placing.
This allows us to use large-scale pretrained vision-language models
like CLIP for what they're good at (identifying task-agnostic vision-language semantics),
while independently learning task-specific manipulation behaviors.
BibTeX
@inproceedings{wangprogrammatically,
title = {Programmatically Grounded, Compositionally Generalizable Robotic Manipulation},
author = {Wang, Renhao and Mao, Jiayuan and Hsu, Joy and Zhao, Hang and Wu, Jiajun and Gao, Yang},
booktitle = {The Eleventh International Conference on Learning Representations}
}